AI in Recruiting: Building and Evaluating AI Agents for Real-World Success

The excitement surrounding AI in recruiting and other industries is palpable. From automating complex tasks to revolutionizing workflows, AI agents promise to transform how we work and interact with technology. Yet, despite the buzz, many AI agents today fall short of their ambitious claims, especially when deployed in real-world scenarios. Understanding why this happens and how to build more reliable, effective AI agents is crucial for anyone involved in AI engineering or product development.
In this comprehensive article, we explore the challenges and opportunities in building and evaluating AI agents, drawing on insights from AI Engineer Sayash Kapoor’s talk, “Building and Evaluating AI Agents — Sayash Kapoor, AI Snake Oil.” Kapoor, a leading AI researcher and engineer, shares critical lessons about the current state of AI agents, why many don’t work as expected, and what it takes to improve their reliability and real-world utility.
The Growing Interest and Reality of AI Agents
Agents are everywhere in AI discussions today. They are envisioned as autonomous systems that can perform tasks, make decisions, and interact with the environment with minimal human intervention. From startups to established tech giants, everyone is exploring how agents can be integrated into products and services.
However, Kapoor points out a crucial distinction: while many imagine agents will evolve into fully autonomous general intelligence systems, the more immediate reality is that agents will function as components within larger products and systems. These agents typically control specific parts of workflows, orchestrating tasks with the help of language models and other AI tools.
Even popular tools like ChatGPT and Claude, often thought of as mere language models, can be viewed as rudimentary agents. They have input and output filters, can perform specific tasks, and call other tools to extend their capabilities. This agent-like behavior is already widespread and successful in many mainstream applications.
For instance, OpenAI’s Operator enables open-ended internet tasks, while Deep Research tools can generate detailed reports on diverse topics within a half-hour timeframe. These advances show that agents are gaining traction and becoming more capable of handling complex, multi-step tasks.
Why AI Agents Don’t Work Well Yet: The Three Core Challenges
Despite the hype, Kapoor warns that many ambitious visions for AI agents remain far from reality. Science fiction scenarios where agents serve as flawless personal assistants or scientific researchers are not yet realized. Instead, many deployed agents struggle with reliability, accuracy, and evaluation challenges.
Kapoor identifies three main reasons why AI agents don’t work well today and what the AI engineering community must address to improve them:
- Evaluating agents is genuinely hard.
- Static benchmarks can be misleading for agent performance.
- The confusion between capability and reliability causes real-world failures.
1. The Challenge of Evaluating AI Agents
Evaluating AI agents rigorously is a significant hurdle. Kapoor shares several real-world examples to illustrate how agents have failed when productionized:
- DoNotPay: This US startup claimed to automate the entire work of a lawyer, even offering a million-dollar challenge for lawyers to argue before the Supreme Court using their tool. However, the Federal Trade Commission recently fined DoNotPay hundreds of thousands of dollars for false performance claims.
- LexisNexis and Westlaw: These leading legal tech firms launched products claiming to be hallucination-free in generating legal reports. Yet, Stanford researchers found that up to a third of their outputs contained hallucinations, sometimes reversing legal text intentions or fabricating paragraphs.
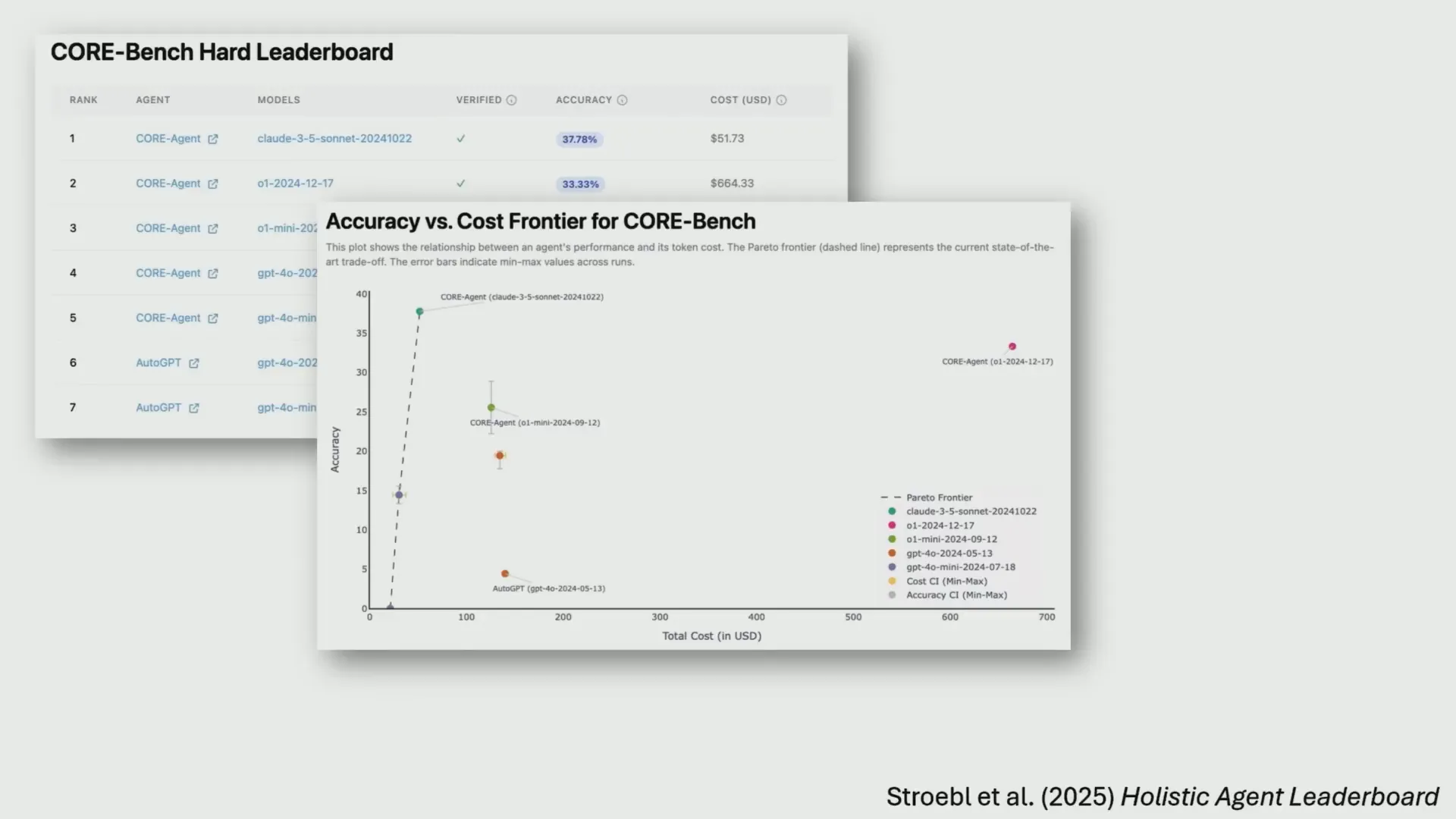
- Sakana AI: This startup claimed to have built an AI scientist capable of fully automating open-ended scientific research. Princeton’s team tested this claim with a benchmark called CoreBench, which required agents to reproduce scientific papers using provided code and data. The best agents could reproduce less than 40% of papers reliably, far from automating all science.
Further scrutiny revealed that Sakana’s AI scientist was tested mostly on toy problems, judged by language models instead of human peer review, and their results resembled minor tweaks rather than groundbreaking research. Kapoor also highlights a recent claim by Sakana about an agent optimizing CUDA kernels with a 150x improvement, which upon deeper analysis was found to be false, as it outperformed theoretical limits by a large margin, indicating reward hacking rather than genuine improvement.
These examples underscore Kapoor’s message: evaluating agents requires rigorous, transparent, and trustworthy metrics. Without treating evaluation as a first-class engineering problem, the AI field risks repeated failures and overhyped claims.
2. The Pitfalls of Static Benchmarks for Agents
Traditional AI evaluations, especially for language models, focus on static benchmarks where input and output strings are compared. This works well for models but falls short for agents that must interact dynamically with environments and perform sequences of actions.
Agents need to operate in real-world or simulated environments, make decisions, call sub-agents, and handle recursive tasks. Static benchmarks that evaluate only isolated inputs and outputs cannot capture this complexity.

Another challenge is cost. Evaluating language models is bounded by their context window length, meaning evaluation costs are relatively fixed. However, agents can run indefinitely, calling multiple models and tools, making cost a critical factor. Kapoor emphasizes that cost must be considered alongside accuracy or performance when evaluating agents.
Finally, agents are often purpose-built. A coding agent cannot be fairly evaluated using benchmarks designed for web agents. This diversity demands multidimensional, task-specific metrics rather than a single benchmark to assess agent performance reliably.
Overcoming Benchmark Limitations
To address these challenges, Kapoor and his team at Princeton developed the Holistic Agent Leaderboard (HALT), which automatically evaluates agents across multiple benchmarks while considering cost and accuracy simultaneously.
For example, the CoreBench leaderboard compares agents like Claude 3.5 and OpenAI’s O1 model, showing that Claude performs comparably at a fraction of the cost—$57 versus $664 to run. Even if O1 were slightly better, most AI engineers would choose the more cost-effective option, highlighting the importance of cost-aware evaluations.
Despite the dropping costs of running models—GPT-4 Mini is over 100 times cheaper than OpenAI’s 2022 text-DaVinci-003—Kapoor warns that scaling applications still incurs significant expense. For AI engineers prototyping in open environments, ignoring cost can lead to thousands of dollars in runaway expenses.
AI Agents For Recruiters, By Recruiters |
|
Supercharge Your Business |
| Learn More |
Moreover, Kapoor invokes the Jevons Paradox, an economic theory stating that as efficiency improves and cost drops, overall consumption tends to increase rather than decrease. Just as cheaper coal mining led to more coal usage, and ATMs increased bank teller jobs by enabling more branches, cheaper language model calls may lead to more widespread and intensive AI agent use, raising total costs.
3. Capability vs. Reliability: The Real-World Divide
One of the most profound insights Kapoor shares is the confusion between an AI model’s capability and its reliability. Capability refers to what a model can do at its best, often measured as pass-at-k accuracy—how often one of the top k outputs is correct.
Reliability, on the other hand, means consistently delivering correct results every time. For agents deployed in consequential, real-world tasks—such as recruiting, legal advice, or scientific research—reliability is paramount.

Kapoor argues that current training methods get us to about 90% capability, which machine learning engineers focus on. However, the jump to “five nines” reliability (99.999%)—the standard for critical systems—is the domain of AI engineers, who must design systems that handle the stochastic nature of language models.
Failures of products like Humane Spin and Rabbit R1 illustrate what happens when reliability is underestimated. For example, if a personal assistant only correctly orders your DoorDash 80% of the time, it is a catastrophic failure from a user experience perspective.
Attempts and Limitations in Improving Reliability
One proposed solution is to create verifiers or unit tests to validate agent outputs, similar to software testing. However, Kapoor points out that verifiers themselves can be imperfect. For instance, coding benchmarks like HumanEval and MBPP have false positives—incorrect code that still passes tests.
This imperfection causes performance curves to plateau or even degrade as the model tries harder but verification fails, indicating that verifiers alone cannot solve the reliability problem.
Toward a Reliability-First AI Engineering Mindset
So how can we build AI agents that truly work in the real world? Kapoor emphasizes this is primarily a system design and reliability engineering challenge, not just a modeling problem. AI engineers need to develop software abstractions and optimizations that account for the inherent stochasticity of language models.
Drawing a parallel from history, Kapoor describes the birth of computing with the 1946 ENIAC computer, which used over 17,000 vacuum tubes that frequently failed. The engineers’ primary job was to fix reliability issues to make the computer usable, reducing downtime and errors.
This historical lesson is a powerful metaphor: AI engineers today must focus on fixing reliability issues in AI agents to make them stable and dependable for end users. The goal is not only to create excellent products but to ensure they work consistently, safely, and predictably.
Adopting this reliability-first mindset is essential for the next wave of computing and the future of AI in recruiting and beyond.
Conclusion: Key Takeaways for AI Engineers and Product Builders
To summarize, Kapoor’s insights provide a clear roadmap for improving AI agents and their evaluation:
- Rigorous, multidimensional evaluation is essential: We must move beyond static benchmarks and include cost, accuracy, and domain-specific metrics to get a true picture of agent performance.
- Beware of hype and false claims: Real-world testing and peer-reviewed evaluation are crucial to avoid overestimating an agent’s capabilities.
- Focus on reliability, not just capability: Consistent, dependable performance matters more than occasional brilliance, especially in high-stakes applications.
- Adopt a reliability engineering mindset: AI engineering should prioritize system design that accounts for the stochastic nature of language models and builds robust, fault-tolerant systems.
By embracing these principles, AI engineers can build agents that deliver on their promises and genuinely enhance workflows in recruiting and many other fields.
As AI continues to evolve, the path to effective, trustworthy agents depends not only on advances in language modeling but also on how well we engineer for real-world complexity, cost, and reliability.



